

那不是机器的轰鸣,而是一位AI工程师在凌晨三点,面对满屏红色错误代码时,发自灵魂深处的疲惫与绝望。一个价值连城的千亿大模型,在耗费了团队数月心血、燃烧了数千万算力成本之后,就在距离“真理”仅一步之遥的瞬间,因为网络中一个比尘埃还小的抖动,轰然崩塌。
这不是危言耸听,这是悬在每一个AI从业者头顶的“达摩克利斯之剑”。我们疯狂地堆砌GPU,构建起一座座庞大的算力“巴别塔”,却发现,连接这些“砖块”的“神经网络”——集合通信库,是如此脆弱。
然而,就在今天,一道划破长夜的闪电,来了!
此刻,请记住这个名字:VCCL(Venus Collective Communication Library)。由创智、基流、智谱AI、中国联通、北航、清华、东南大学——这七位代表着中国AI领域产、学、研巅峰力量的“巨擘”联手,向全世界投下了一枚重磅开源炸弹!
这绝非一次寻常的技术更新,这是一场针对AI基础设施“心脏病”的精准外科手术!它如同一把神之钥匙,将彻底解开束缚GPU性能的最后一道枷锁,让AI大模型训练的稳定性和效率,跃迁至一个我们曾只敢在梦中想象的全新维度。这不仅是一个工具的诞生,更是一个时代的宣言:在人工智能最核心的战场上,我们来了,带着定义未来的力量!
“午夜惊魂”,万卡集群下的“钢铁巨人”与“阿喀琉斯之踵”
让我们将镜头拉近,走进AI工程师小王(举例)的“战场”。
他的战场,没有硝烟,却比任何战场都更惊心动魄。那是一片由成千上万台服务器组成的“钢铁森林”,无数蓝色指示灯如深邃的星海,闪烁着智慧的光芒。空气中弥漫着冰冷的、被制冷系统过滤后的独特气味,混合着机器低沉的嘶吼,仿佛一头正在沉睡的远古巨兽。
小王和他的团队(举例),正是这头巨兽的“驯养师”。他们倾注心血的项目——“启明5.0”,一个旨在加速新药研发、模拟蛋白质折叠的千亿参数大模型,已经在这片钢铁森林中不间断地“修炼”了92天。每一秒,都有海量的算力在燃烧,每一次参数的更新,都可能意味着人类距离攻克某种顽疾又近了一步。希望与压力,在这里交织到了极致。
然而,那个凌晨,魔鬼露出了它的獠牙。
“滴!滴!滴!”刺耳的告警声如同一把锋利的冰锥,瞬间撕裂了小王浅薄的睡意。他从行军床上猛地弹起,心脏仿佛被一只无形的手攥紧。冲到屏幕前,那熟悉的绿色进度条已荡然无存,取而代之的,是瀑布般倾泻而下的红色错误日志,像一场突如其来的雪崩,瞬间吞噬了所有的希望。
“通信超时……节点失联……”
又是它!那个潜伏在万卡集群深处的“阿喀琉斯之踵”——通信故障。仅仅因为一台交换机的某个端口出现了微秒级的抖动,整个庞大的“神经网络”便陷入了瘫痪。传统的通信库(如NVIDIA的NCCL)就像一个固执的“一根筋”,它只会通过漫长的“超时等待”来判断队友是否掉线,一旦确认,便粗暴地中断整个任务。
小王瘫坐在椅子上,眼中布满血丝。他知道,这不仅仅是损失了几个小时的宝贵时间。团队需要像侦探一样,在浩如烟海的日志中艰难地寻找那个“肇事”的端口;然后,是漫长的任务回滚,从数小时前甚至一天前的检查点(checkpoint)重新开始。这感觉,就像你精心建造的万丈高楼,在即将封顶时,被人从地基抽走了一块砖。
“我们不仅损失了三天的有效算力,”项目负责人在晨会上声音沙哑,“更重要的是,我们可能错过了那个稍纵即逝的‘灵感窗口’,下一次模型能收敛到这个程度,谁也不知道要等到什么时候。”
团队里一片死寂,每个人的脸上都写满了挫败。小王的故事,是整个AIGC行业在迈向“万卡时代”时,共同的“成长之痛”。当算力的规模以指数级膨胀,硬件的故障便从“偶然事件”变成了“必然常态”。如何让这个庞大而脆弱的“钢铁巨人”拥有一套真正稳定、高效、智能的“神经系统”,成为了比单纯追求更高算力更为紧迫的课题。
而VCCL,正是带着这份使命,应运而生。
VCCL“亮剑”,三大神技重塑AI“神经网络”
VCCL,全称“启明女神集合通信库”,这个名字本身就寓意着智慧与光明。它并非对现有技术的简单修补,而是一次从底层逻辑出发的颠覆性重构。它亮出了三把“神剑”,直指AI训练的核心痛点。
效率之剑——“无感通信”,让GPU化身“专注的艺术家”
想象一下,一位世界顶级的小提琴家正在演奏一首华丽的乐章,如果他需要时不时停下来自己翻乐谱,那演奏的流畅性必然大打折扣。过去的通信库,就常常让GPU(小提琴家)分心去做“翻乐谱”(通信协调)的杂事。
而VCCL,则像一位技艺超凡、心有灵犀的“指挥家”。它通过SM-Free和Zero-Copy等核心技术,将几乎所有的通信任务都巧妙地“卸载”给了CPU。GPU这颗宝贵的“大脑”从此被彻底解放,可以120%地专注于它最擅长的事情——计算。它甚至感觉不到通信的存在,数据就已经如丝般顺滑地在节点间流淌。
结果是惊人的:在不同规模的集群实测中,VCCL将端到端的算力利用率稳定提升了2%到6%! 在千卡集群上,通信耗时平均降低18%,带宽利用率更是飙升至92%,几乎触碰到了硬件的物理天花板!这2%-6%的提升,对于一个万卡集群来说,意味着每天可以节省下数百万的成本,或者说,将模型的研发周期缩短数周!
稳定之剑——“智能高速网”,告别“一断全崩”
如果说传统的NCCL像一条单轨列车,任何一处铁轨损坏(链路故障),整条线路都会瘫痪。那么VCCL,则构建了一张智能化的“算力高速公路网”。
它内置了一套革命性的快速容错机制。当某条“车道”(网络链路)出现拥堵或损坏时,VCCL的智能调度系统会在毫秒之内感知到,并立刻像最高效的导航软件一样,规划出一条全新的、通畅的“备用路线”,引导数据流无缝切换过去。整个过程对上层的训练任务完全透明,AI模型甚至不知道自己刚刚经历了一场“网络惊魂”。
这一剑,直接将集群的整体故障率爆降了超过50%,故障恢复时间更是缩短了40%以上! 这意味着,像小王那样的“午夜惊魂”将成为历史。VCCL如同一位永不疲倦的“守护神”,让大模型训练从“走钢丝”变成了“高速巡航”,为动辄数月、耗资巨大的训练任务提供了前所未有的“保险”。
洞察之剑——“流量核磁共振”,让网络黑箱无所遁形
过去,排查智算中心的网络性能问题,就像是给一个只会说“不舒服”的病人看病,医生(工程师)只能靠猜。
VCCL带来的Flow Telemetry技术,则彻底改变了这一局面。它就像是为整个通信网络做了一次超高精度的“核磁共振成像”。工程师们可以清晰地“看”到每一对GPU之间、在每一毫秒内的数据流速、延迟和拥塞情况。网络中的任何一个细微的性能瓶颈,都会像MRI图像上的病灶一样,被精准地定位和可视化。
这种“上帝视角”让网络优化从一门“玄学”变成了一门“科学”。工程师们可以基于精确的数据,进行外科手术式的精准调优,将整个集群的通信效率推向极致。
“梦之队”集结,一次产学研的“中国式合奏”
如此强大的VCCL,其背后是一支堪称“中国AI复仇者联盟”的梦之队。这并非一次简单的商业合作,而是一场怀揣着共同理想的、深度融合的“集结号”。
1-创智与基流,这两位AI基础设施领域的“架构大师”,凭借对系统底层的深刻理解,绘制了VCCL的宏伟蓝图。
2-智谱AI,这位身经百战的“沙场老将”,在自家GLM大模型的真实、严苛的生产环境中,对VCCL进行了千锤百炼的“实战检验”,确保了它的稳定与高效。
3-中国联通,这位手握庞大算力网络的“基建巨擘”,提供了广阔的试验场和宝贵的异构环境运维经验,让VCCL拥有了强大的普适性。
清华、北航、东南大学,这些学术界的“思想引擎”,则为VCCL注入了最前沿的理论创新和源源不断的智慧火花。
他们,有的来自炮火连天的产业一线,有的来自宁静致远的象牙塔尖。但今天,他们为了一个共同的目标走到了一起:打造属于我们自己的、世界一流的AI核心基础设施,将数字时代“算力高速公路”的规则制定权,牢牢掌握在自己手中!
开源,是最大的自信;未来,已在我们手中!
今天,VCCL选择以“开源”的方式,向世界敞开怀抱。
这不仅仅是一个软件库的开源,它更像是在数字世界里,我们铺设的第一条拥有完全自主知识产权的“智能高铁”轨道。它向世界宣告:我们不仅能建造摩天大楼,我们更能从最深处打下坚实的地基!
开源,是最大的自信。它是一封发给全球开发者的“英雄帖”,邀请所有人共同见证、参与并塑造一个更加开放、高效、稳定的AI新纪元。
创智、基流、智谱、联通、北航、清华、东南联合打造了高效率、高可靠、高可视的 GPU 集合通信库 VCCL(Venus Collective Communication Library),VCCL 已部署于多个生产环境集群中。
开源代码与文档仓库:https://github.com/sii-research/VCCL
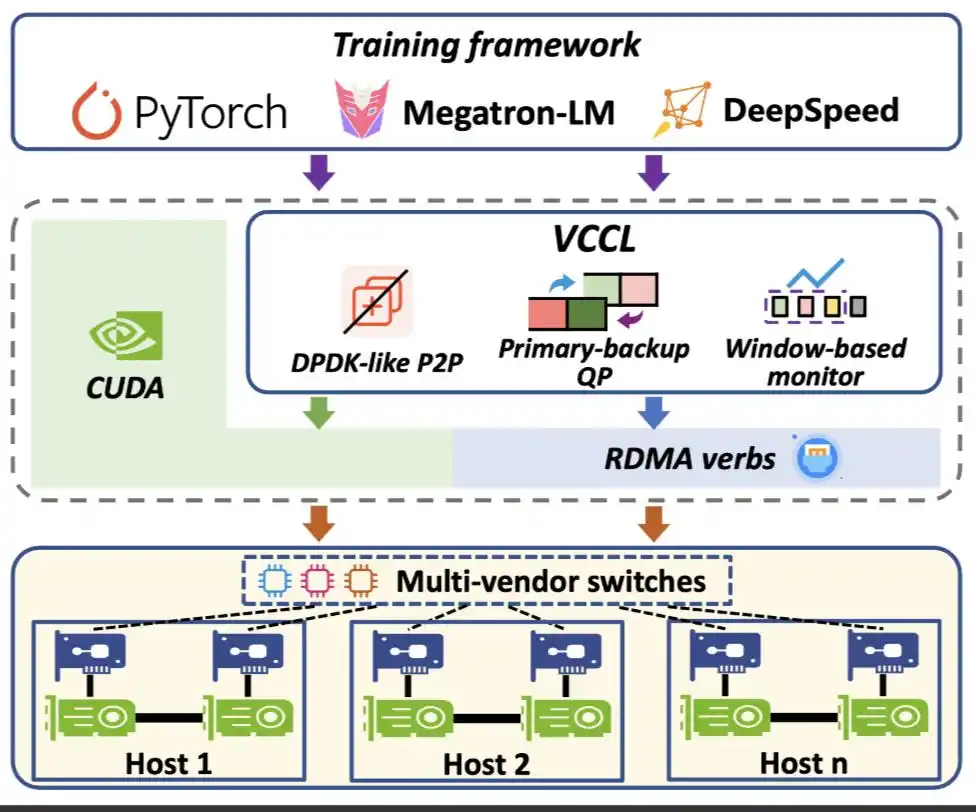
VCCL 的系统架构如下图所示,作为通信中间件,支撑训练框架,兼容异构硬件设备。VCCL 基于 NCCL 开发,在通信组启动逻辑(拓扑搜索、网络图构建和信道建立)之上,引入三个关键组件:
VCCL 的目标不仅是提升通信效率,更是要让 GPU 算力得到最大化释放,通过 DPDK-like P2P 智能调度,VCCL 将通信任务合理卸载至 CPU,并在 PP(Pipeline Parallel) 工作流中实现深度交叠和全局负载均衡,大幅缩短 GPU 空闲时间。实测显示基于开源框架 Megatron-LM 的 SOTA 性能,使用 VCCL 后的 Dense 模型训练端到端算力利用率可进一步提升 2%-6%。
超大规模智算集群中,网络故障几乎是不可避免的风险源,VCCL 设计了一套基于 Primary-backup QP 链接的容错机制,在不增加系统负担的前提下,大幅提升整体稳定性。通过这一机制,VCCL 能够将集群故障率降低超过 50%,真正做到 “网络出故障了也能原地拉回”,让大模型训练不再轻易被打断。
VCCL 设计了 Flow Telemetry,一种微妙级的 GPU 间点对点流量观测机制,能够清晰捕捉训练过程中通信速率的细微变化,为研发团队提供更细粒度的网络可观测能力,可有效解决传统基于计数的统计方式粒度粗、准确度差的问题,支持定位训练过程中的慢节点或慢链路。
设计 1:DPDK-like P2P 智能调度
问题挑战:P2P 通信的高 SM 占用和复杂操作。GPU SM(Streaming Multiprocessor)流式多处理器是英伟达 GPU 的核心计算单元,包含 CUDA 核心、寄存器、缓存等组件。编程人员编写核函数,由 CUDA 运行时来进行任务调度。我们发现,NCCL P2P 通信没有涉及规约操作,但仍然占用了不低的 SM 资源,同时 NCCL P2P 操作引入多步与通信无关的操作,拖慢了整体性能。下表是使用两台 GPU 服务器运行 NCCL-Tests 统计的 P2P SM 资源占用情况。下图是 P2P 操作中开销统计,其中约 25% 的时间用于显存拷贝。
计算机体系结构的演进具有周期性和相似性,一个技术方向演进总是从功能到性能,架构设计也倾向于从通用到专用。CUDA 是一个黑盒,计算通信的调度效率低,API 接口有限,优化难度大,与 Linux 内核相似。
15 年前,随着云计算发展,网络数据流量以前所未有的速度增长,对网络处理性能的要求也达到了极致。传统的基于内核的网络数据包处理方式已无法满足现代高速网络设备的需求。DPDK(Data Plane Development Kit) 应运而生,目前已运行于每一台云数据中心的 CPU 服务器中。DPDK 将网络数据平面处理从内核态迁移至用户态,采用轮询而非中断方式进行数据收发调度,并通过大页内存无锁零拷贝的方式加速数据传输。
VCCL 提出 DPDK-like P2P 设计,与 DPDK 优化 Linux 内核协议栈的网络处理一致,VCCL 对 CUDA 侧的通信处理进行优化:
SM-Free P2P,在训练过程中 GPU 服务器的 CPU 利用率往往很低,VCCL 绕过 CUDA 内部对 P2P 的调度和处理机制,将 P2P 操作卸载至 CPU 运行,无需启动任何 CUDA 核函数,实现 SM-Free。SM-Free 的实现并不直接,P2P 在 CPU 侧运行缺少同步机制,无法保证 GPU 计算流的依赖关系。VCCL 采用 CUDA cudaLaunchHostFunc 编程接口,通过 CPU 侧轮询机制进行操作同步,并在工程上解决了多种隐藏卡死(Hang)问题。
Zero-Copy P2P,传统 CUDA 通信中,会分配块缓存(chunk buffer),将应用缓存(application buffer)拷贝至块缓存,VCCL 使用 User Buffer Registration 机制,通过 ncclMemAlloc 接口,直接将应用数据映射至网卡。Zero-Copy 设计也有效防止了因为多方 I/O 访问带来的卡死问题。
Deep PP Overlap,VCCL SM-Free P2P 设计可以进一步消除传统 GEMM 计算和 P2P 通信的 SM 竞争。这部分竞争,受限于 CUDA 调度机制,在传统 PP 计算通信交叠中无法消除。VCCL SM-Free P2P 可以给计算分配更多 SM 资源,同时 VCCL 在 PP 切分中使能全局负载均衡,最终将通信深度交叠于计算之内。
设计 2:Primary-backup QP 原地恢复容错
问题挑战:网络抖动是发生最多的故障类别。在大规模分布式训练中,网络抖动相关的链路故障(如,网口 Down、交换机异常等)占比超过 GPU 故障和其他故障。我们统计了一个数千卡规模的 GPU 集群在 2024 年 3 月至 12 月的故障情况。一旦发生网络故障,对应的通信队列对(QP,Queue Pair)在超时后无法继续发送,会触发 AEQ 事件并立刻进入 ERR 状态,结果是整体集合通信操作被卡死(hang),大模型训练直接失败,待到超时时间结束,任务才会被 watchdog 强制退出。
面对网络链路故障,现有的业界方案往往难以满足训练过程中的即时恢复需求:
NCCL,依赖 timeout 参数,往往意味着训练中断与长时间等待。
checkpoint,虽然可以缩短故障恢复时间,但依然需要重启或回滚,无法保证训练的连续性。
网口聚合,适合应对突发的网口 Down,无法适用于单端口集群场景,不支持交换机故障容忍。
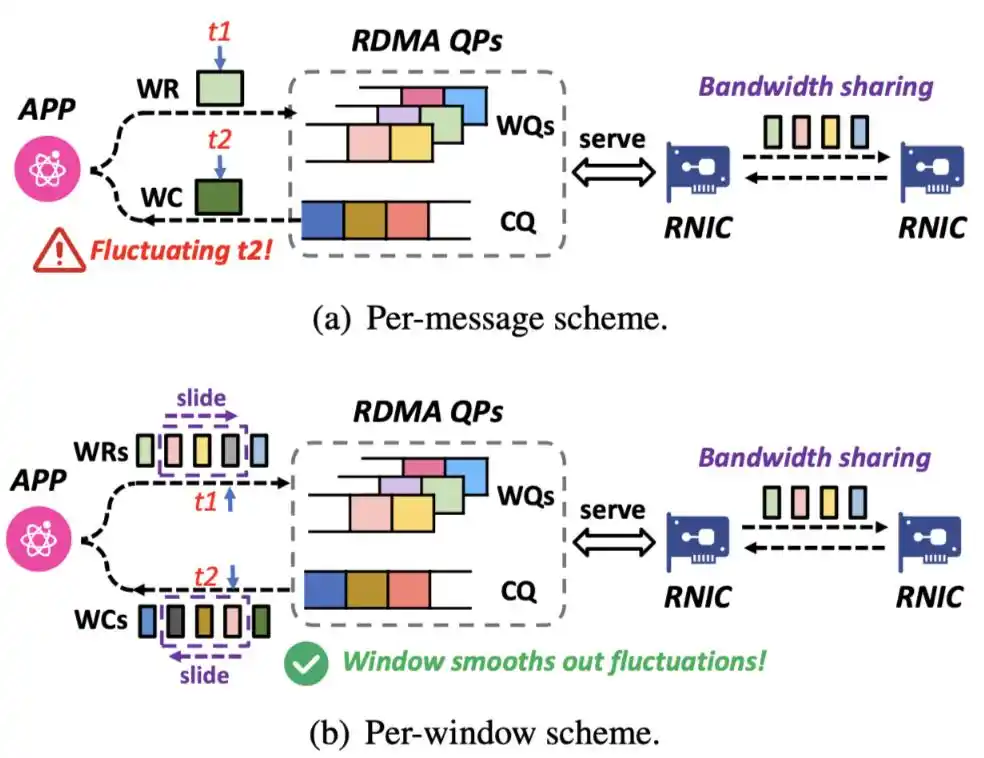
VCCL 提出更通用且成本更低的 Primary-backup QP 设计,进行原地恢复。在通信组启动过程中,VCCL 为每一个主通信队列对,建立一个备份通信队列对。当网络出现故障时,VCCL 能在底层实时检测,自动将流量无差别导向备份网口完成通信。整个过程无需应用层感知,无需额外干预。当原链路恢复后,VCCL 会检测并将流量切换回主通信队列对,集合通信性能完全恢复。
VCCL Primary-backup QP 设计的核心在于状态同步和迁移。如下图所示,VCCL 使用三个指针代表收发两端的传输和接受状态。在发送端,posted 代表应用准备好的数据,transmitted 代表网络代理准备在网卡发送的数据,acked 代表已发送并确认收到的数据。在接收端,posted 含义一致,received 与 transmitted 对应代表准备接收的数据,done 与 acked 对应代表确认收到的数据。网络链路故障时,VCCL 采用接收端驱动的机制,从最后一个确认的数据块开始重传。VCCL 采用定时检测的机制,在完成网络链路恢复时,切换回主通信队列对。
设计 3:Flow Telemetry 细粒度可视化
问题挑战:集群故障定位与性能分析缺少有效工具。由于集合通信操作同时涉及 GPU 计算与网络传输,集群任务故障发生时的大部分报错都与 NCCL error 相关,包括训练任务卡死、降速等问题。传统手段需要大量人工介入,而且故障难以复现,对于大任务停集群排障是一件代价极高的事情。造成当前问题的核心在于,缺少对集合通信的细粒度且在线监测工具,现有的网络监控工具都处在秒级粒度,而集合通信操作通常在毫秒级甚至微秒级完成。
VCCL 提出 Flow Telemetry 设计,利用 RDMA 编程的细腰抽象,所有集合通信操作都可以拆解为微秒级 RDMA verbs 代表的网卡侧数据发送传输语义。基于集合通信消息的监测采集机制,会因为多个消息共享链路带宽而造成统计不准确问题。VCCL 进一步采用滑动窗口机制,在同一通信队列对中,统计所有相关消息的平均瞬时带宽,得到集合通信层的微秒级统计数据。
VCCL Flow Telemetry 支持 GPU 间微秒级别流量探测,能够清晰捕捉训练过程中通信速率的细微变化,以此作为基准可进一步确定计算和通信操作的运行时间点,定位集群任务卡死原因,分析慢节点。同时,Flow Telemetry 能够实时统计端口上未完成的 RDMA WR(Work Request)数量,并据此推测工作队列长度变化,从而精准判断网络是否出现拥塞。
实验评测
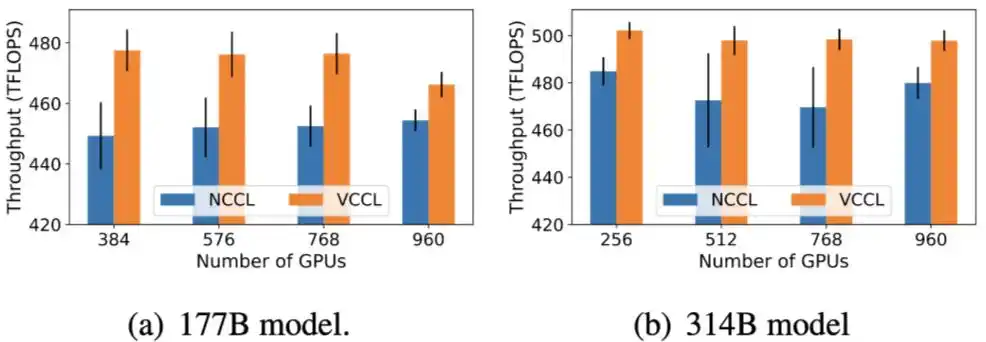
VCCL 基于 NCCL v2.21.5 实现,采用千卡英伟达 Hopper GPU RoCEv2 集群进行评测,以最佳实践超参数运行 Megatron-LM 自带的 GPT-2 6B、32B、70B、177B、314B 大小模型。
DPDK-like P2P 对效率的提升
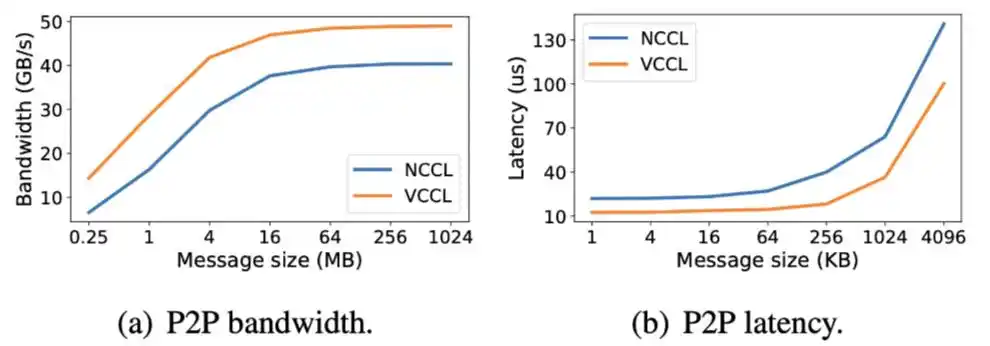
比较 VCCL 和 NCCL 的 P2P 性能。在不同消息大小下,通过 NCCL-Test 测试 VCCL 和 NCCL 的 send/recv 操作,VCCL 在 1GB 消息大小下算法带宽比 NCCL 提升 20.12%,VCCL 在小消息下时延比 NCCL 降低至少 28.5%。VCCL 在实现 P2P 操作 SM 零占用的前提下,对于 CPU 的使用,只比 NCCL 增加了 4%。
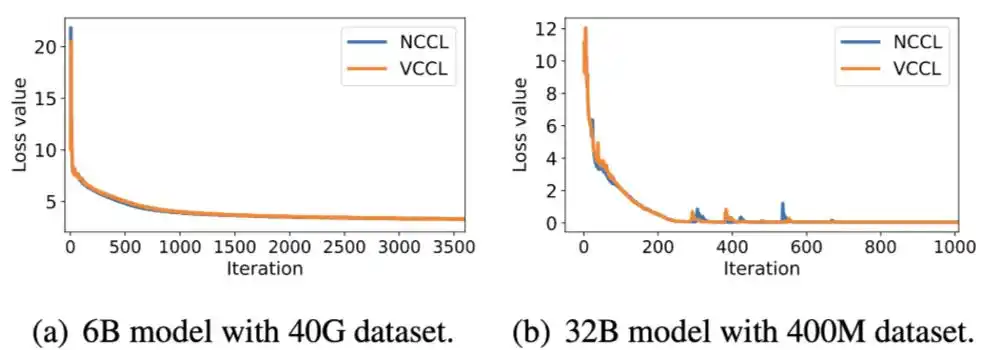
分别使用 VCCL 和 NCCL 运行 Megatron-LM,测试训练准确性和算力利用率。VCCL 与 NCCL 的 Loos 收敛曲线一致,VCCL DPDK-like P2P 的设计保证了计算和通信的正确调用顺序。在不同模型大小和集群规模下,端到端算力利用率 VCCL 比 NCCL 有 2%-6% 提升,体现出 SM-Free、Zero-Copy 以及 PP 深度交叠带来的新的性能增益。
Primary-backup QP 对可用性的提升
采用手动方式在第 4 秒和第 19 秒之间 Down 掉网卡端口,在第 4 秒和第 19 秒之间,VCCL 和 NCCL 同时在执行重试机制,第 14 秒后重试机制结束,NCCL 的集合通信带宽无法恢复,而 VCCL 通过切换备用通信队列对,仍然可以保持,76.6% 的 AllReduce 带宽和 58.1% 的 ReduceScatter 带宽,19 秒后 VCCL 切换回主通信队列对,性能恢复正常。在采用备用通信队列对时,Down 掉一个网卡端口,VCCL 只引入 0.38% 的算力利用率下降,与正常运行时的算力利用率基本一致。
Flow Telemetry 对可视化的提升
验证 VCCL Flow Telemetry 的毫秒级监测功能,分别在窗口大小为 1、8、32 的情况下,以 10 微妙粒度呈现 P2P 吞吐量。当窗口大小设为 1 时,等价于消息粒度的监测,波动较大;当窗口大小为 32 时,VCCL 可以平滑展示吞吐量,但缺少瞬时波动的呈现。实验显示,窗口大小设置为 8 时,可以平衡监测的准确度和平滑性。
VCCL 部署与展望
VCCL 在实际部署过程中,还解决了服务器机型异构的问题。不同厂商的服务器,因 PCIe 拓扑结构差异导致跨设备连接不通及多网卡端口间流量不均衡,致使 RDMA 性能未达预期。为系统性地解决此问题,VCCL 针对不同硬件配置设计了相应的优化方案。
VCCL 在线运行过程中,用户会遇到一些集群问题,包括集合通信报错或者训练性能下降。但会存在定位出的根因与通信无关的情况,相关案例包括:云平台参数配置错误导致 CPU 核心分配不足;GPU 服务器风扇转速配置错误;GPU 单卡执行任务故障等。这些问题字面上看似简单,但集群黑盒分析起来挑战很大,多维度在线故障定位与性能分析工具需要持续迭代优化。
VCCL 的容错机制可以更好地包容网络硬件设备的故障,也为创新或国产化网络组件上线部署提供冗余度空间,有效助力于算力生态发展。
VCCL 让团队看到了更高性能、更高稳定性的集合通信库发展机遇,未来 VCCL 会支持适配更多并行工作流、MoE 等模型结构、新型硬件架构。


关注公众号
即时获知最新推送
休闲时刻
陶冶艺术情操
Copyright © 2015 Science And Technology Investment Network.All Rights Reserved 版权所有:数智化网
地址:北京市海淀区翠微中里14号楼
